Linux Console is a dinosaur and a stone age relics. There isn't too much you can do for its keyboard driver. But under X windows, since the new Linux Input framework (evdev) is utilized, you have full-fledged customization capability, with the corresponding complexity. Here are some background materials. Read them before we got lost during our keyboard customization:
http://www.x.org/releases/current/doc/kbproto/xkbproto.pdf
http://www.linuxjournal.com/article/6396
http://www.linuxjournal.com/article/6429
https://wiki.archlinux.org/index.php/X_KeyBoard_extension
http://en.wikipedia.org/wiki/Evdev
http://www.x.org/archive/X11R7.5/doc/input/XKB-Config.html
http://www.charvolant.org/~doug/xkb/
http://who-t.blogspot.com/
1. Packages:KeyRelease event, serial 32, synthetic NO, window 0x1800001,
root 0xb4, subw 0x0, time 30859749, (380,920), root:(1344,1036),
state 0x0, keycode 111 (keysym 0xff52, Up), same_screen YES,
XLookupString gives 0 bytes:
XFilterEvent returns: False
KeyPress event, serial 32, synthetic NO, window 0x1800001,
root 0xb4, subw 0x0, time 31122837, (410,486), root:(1374,602),
state 0x1, keycode 38 (keysym 0x41, A), same_screen YES,
XLookupString gives 1 bytes: (41) "A"
XmbLookupString gives 1 bytes: (41) "A"
XFilterEvent returns: False
Compiler and loader:
extra/xkeyboard-config: all the configurable keymap data
extra/xorg-xkbcomp: xkb configuration file compiler. You need it to compile you customized keymap. It can also load your keymap. The top gun for xkb configuration.
extra/xorg-setxkbmap: a convenient tool to load xkb configuration. A subset of xorg-xkbcomp.
extra/xorg-xmodmap: a legacy tool to modify current keymap. Not recommended. Use xorg-setxkbmap/xorg-xkbcomp instead.
extra/xorg-xset: set keyboard repeat rate, repeat delay, dpms, screen saver, misc stuff
systemd localectl: it also load and change keymap. Since systemd-localed is a service, it is the best place to put your default keymap configuration, both for console and X;
Monitoring tools:
When you are dealing with keyboard, it is critical to have a good monitoring tool, since you will mess up every easily and have to reboot machine to gain your keboard back.
extra/xorg-xinput: keyboard/mouse/trackpad event capture, from the level of X Windows application programmer;
extra/xorg-xev: similiar to xorg-xinput, also from the X application perspective. The most suitable tool for our current job.
aur/evtest: event tracker from xorg driver/device perspective. It report events from kernel, through device node under /dev/input/eventX, before they are hanled by Xorg input evdev driver;
aur/evemu: upgraded version of "evtest". can capture and replay event. The top gun test suite, overkill for our current job.
aur/xkbprint: print out a keyboard image per your current configuration so you know "visually" how your keyboard look like. Good if you got so lost and don't know what you have done to your keyboard configuration.
xorg keyboard input driver:
xf86-input-evdev: all internal and external keyboards all use driver. It also handle mouse input of external usb mouse. The apple trackpad is handled by another driver xf86-input-synaptics. We will discuss touchpad tuning in later post.
2. status quo
[luke@rmbp ~]$ localectl
System Locale: LANG=en_US.UTF-8
VC Keymap: us
X11 Layout: us
A complete and functional xkb configuration consists of 5 components, as told by "setxkbmap -print": keycodes,types,compat,symbols,geometry. All these components reside under "/usr/share/X11/xkb":
[luke@rmbp xkb]$ ll /usr/share/X11/xkb
total 24
drwxr-xr-x 2 root root 4096 Feb 4 20:11 compat
drwxr-xr-x 4 root root 4096 Feb 4 20:11 geometry
drwxr-xr-x 4 root root 4096 Feb 4 20:11 keycodes
drwxr-xr-x 2 root root 4096 Feb 4 20:11 rules
drwxr-xr-x 13 root root 4096 Feb 4 20:11 symbols
drwxr-xr-x 2 root root 4096 Feb 4 20:11 types
![]()
I have external USB logitech keyboard. Let us do some experiments with logitech plugged in.
[luke@rmbp ~]$ xinput list
⎡ Virtual core pointer id=2[master pointer (3)]
⎜ ↳ Virtual core XTEST pointer id=4[slave pointer (2)]
⎜ ↳ bcm5974 id=10[slave pointer (2)]
⎜ ↳ Logitech USB Receiver id=12[slave pointer (2)]
⎣ Virtual core keyboard id=3[master keyboard (2)]
↳ Virtual core XTEST keyboard id=5[slave keyboard (3)]
↳ Power Button id=6[slave keyboard (3)]
↳ Power Button id=7[slave keyboard (3)]
↳ Sleep Button id=8[slave keyboard (3)]
↳ Apple Inc. Apple Internal Keyboard / Trackpadid=9[slave keyboard (3)]
↳ Logitech USB Receiver id=11[slave keyboard (3)]
localectl actually write a X keyboard config file into "/etc/X11/xorg.conf.d/00-keyboard.conf".
I can also add just add a line into my .xinitrc:
setxkbmap -model macbook78 -layout us -option "terminate:ctrl_alt_bksp"
3. "command" key customization
It is finally time to add my humble customization of "command" key, based on selected macbook78 configuration. Under X, I can not simply remap "command" to "control", since "command" key is well defined under X, as can be seen from the output of "xev":
KeyRelease event, serial 32, synthetic NO, window 0x1800001,
root 0xb4, subw 0x0, time 7870193, (455,915), root:(2379,955),
state 0x40, keycode 133 (keysym 0xffeb, Super_L), same_screen YES,
XLookupString gives 0 bytes:
XFilterEvent returns: False
KeyRelease event, serial 32, synthetic NO, window 0x1800001,
root 0xb4, subw 0x0, time 7870689, (455,915), root:(2379,955),
state 0x40, keycode 134 (keysym 0xffec, Super_R), same_screen YES,
XLookupString gives 0 bytes:
XFilterEvent returns: False
These definitions basically says: " Keycode of Commnad/L/R are 133/134, with alias "LMTA/RMTA"; bothhttp://www.x.org/releases/current/doc/kbproto/xkbproto.pdf command keys are mapped to "physical" modifier key "Mod4"; the key symbols for command/L/R are "Super_L" and "Super_R"; Both "Super_L" and "Super_R" are mapped to "virtualModifier Super".
Under Xkb, the mapping between keycode and key symbols are affected by the "type" of a keycode. A type basically defines how many "levels" of mappings could one keycode has, and with what modifiers to represent which level. Types are defined in xkb_types, for example:
type "ONE_LEVEL" {
modifiers= none;
level_name[Level1]= "Any";
};
type "TWO_LEVEL" {
modifiers= Shift;
map[Shift]= Level2;
level_name[Level1]= "Base";
level_name[Level2]= "Shift";
};
type "ALPHABETIC" {
modifiers= Shift+Lock;
map[Shift]= Level2;
map[Lock]= Level2;
level_name[Level1]= "Base";
level_name[Level2]= "Caps";
};
type "CTRL+ALT" {
modifiers= Shift+Control+Alt+LevelThree;
map[Shift]= Level2;
preserve[Shift]= Shift;
map[LevelThree]= Level3;
map[Shift+LevelThree]= Level4;
preserve[Shift+LevelThree]= Shift;
map[Control+Alt]= Level5;
level_name[Level1]= "Base";
level_name[Level2]= "Shift";
level_name[Level3]= "Alt Base";
level_name[Level4]= "Shift Alt";
level_name[Level5]= "Ctrl+Alt";
};
[luke@rmbp xkb]$ cat ./keymap/macbook78
You can find all source codes under Github, follow below links:
https://github.com/lukeluo/linux-debian7-admin/tree/master/archlinux/home/luke/xkb
Now we have all the modification, we need to compile our keymap:
# first compile into text form, check if it is correct
http://www.x.org/releases/current/doc/kbproto/xkbproto.pdf
http://www.linuxjournal.com/article/6396
http://www.linuxjournal.com/article/6429
https://wiki.archlinux.org/index.php/X_KeyBoard_extension
http://en.wikipedia.org/wiki/Evdev
http://www.x.org/archive/X11R7.5/doc/input/XKB-Config.html
http://www.charvolant.org/~doug/xkb/
http://who-t.blogspot.com/
1. Packages:KeyRelease event, serial 32, synthetic NO, window 0x1800001,
root 0xb4, subw 0x0, time 30859749, (380,920), root:(1344,1036),
state 0x0, keycode 111 (keysym 0xff52, Up), same_screen YES,
XLookupString gives 0 bytes:
XFilterEvent returns: False
KeyPress event, serial 32, synthetic NO, window 0x1800001,
root 0xb4, subw 0x0, time 31122837, (410,486), root:(1374,602),
state 0x1, keycode 38 (keysym 0x41, A), same_screen YES,
XLookupString gives 1 bytes: (41) "A"
XmbLookupString gives 1 bytes: (41) "A"
XFilterEvent returns: False
Compiler and loader:
extra/xkeyboard-config: all the configurable keymap data
extra/xorg-xkbcomp: xkb configuration file compiler. You need it to compile you customized keymap. It can also load your keymap. The top gun for xkb configuration.
extra/xorg-setxkbmap: a convenient tool to load xkb configuration. A subset of xorg-xkbcomp.
extra/xorg-xmodmap: a legacy tool to modify current keymap. Not recommended. Use xorg-setxkbmap/xorg-xkbcomp instead.
extra/xorg-xset: set keyboard repeat rate, repeat delay, dpms, screen saver, misc stuff
systemd localectl: it also load and change keymap. Since systemd-localed is a service, it is the best place to put your default keymap configuration, both for console and X;
Monitoring tools:
When you are dealing with keyboard, it is critical to have a good monitoring tool, since you will mess up every easily and have to reboot machine to gain your keboard back.
extra/xorg-xinput: keyboard/mouse/trackpad event capture, from the level of X Windows application programmer;
extra/xorg-xev: similiar to xorg-xinput, also from the X application perspective. The most suitable tool for our current job.
aur/evtest: event tracker from xorg driver/device perspective. It report events from kernel, through device node under /dev/input/eventX, before they are hanled by Xorg input evdev driver;
aur/evemu: upgraded version of "evtest". can capture and replay event. The top gun test suite, overkill for our current job.
aur/xkbprint: print out a keyboard image per your current configuration so you know "visually" how your keyboard look like. Good if you got so lost and don't know what you have done to your keyboard configuration.
xorg keyboard input driver:
xf86-input-evdev: all internal and external keyboards all use driver. It also handle mouse input of external usb mouse. The apple trackpad is handled by another driver xf86-input-synaptics. We will discuss touchpad tuning in later post.
2. status quo
[luke@rmbp ~]$ localectl
System Locale: LANG=en_US.UTF-8
VC Keymap: us
X11 Layout: us
[luke@rmbp ~]$ setxkbmap -print
xkb_keymap {
xkb_keycodes { include "evdev+aliases(qwerty)"};
xkb_types { include "complete"};
xkb_compat { include "complete"};
xkb_symbols { include "pc+us+inet(evdev)"};
xkb_geometry { include "pc(pc104)"};
};
A complete and functional xkb configuration consists of 5 components, as told by "setxkbmap -print": keycodes,types,compat,symbols,geometry. All these components reside under "/usr/share/X11/xkb":
[luke@rmbp xkb]$ ll /usr/share/X11/xkb
total 24
drwxr-xr-x 2 root root 4096 Feb 4 20:11 compat
drwxr-xr-x 4 root root 4096 Feb 4 20:11 geometry
drwxr-xr-x 4 root root 4096 Feb 4 20:11 keycodes
drwxr-xr-x 2 root root 4096 Feb 4 20:11 rules
drwxr-xr-x 13 root root 4096 Feb 4 20:11 symbols
drwxr-xr-x 2 root root 4096 Feb 4 20:11 types
You should already known what "keycodes" are. Under xkb, keycode are all equipped with symbolic names. We should stick to symbolic names instead of numeric values for compatibility issue. All files under "/keycodes" are about assigning symbolic name to keycode. Keycode symbolic names can have aliases name. Please be reminded that keycode values for the same physical key are different between linux console and xkb. In our case, keycodes are defined by "evdev+aliases(qwerty)". We can checkout "keycodes/evdev" and "keycodes/aliases" to see what keycodes are available under current configuration. We can see the keycode ranges from 8 to 255 under "evdev" too.
[luke@rmbp keycodes]$ cat evdev
// translation from evdev scancodes to something resembling xfree86 keycodes.
default xkb_keycodes "evdev" {
minimum = 8;
maximum = 255;
# Added for pc105 compatibility
<LSGT> = 94;
<TLDE> = 49;
<AE01> = 10;
<AE02> = 11;
..............................
[luke@rmbp keycodes]$ cat aliases
http://www.x.org/releases/current/doc/kbproto/xkbproto.pdf
// keycode aliases for phonetic keyboard maps
default
xkb_keycodes "qwerty" {
alias <LatQ> = <AD01>;
alias <LatW> = <AD02>;
alias <LatE> = <AD03>;
alias <LatR> = <AD04>;
alias <LatT> = <AD05>;
................................
It is time to use "xev" to get some feeling on the "keycodes". Check the output of evdev with the definition in "evdev" file. Make sure that they match:
KeyRelease event, serial 32, synthetic NO, window 0x1800001,
root 0xb4, subw 0x0, time 30859749, (380,920), root:(1344,1036),
state 0x0, keycode 111 (keysym 0xff52, Up), same_screen YES,
XLookupString gives 0 bytes:
XFilterEvent returns: False
KeyPress event, serial 32, synthetic NO, window 0x1800001,
root 0xb4, subw 0x0, time 31122837, (410,486), root:(1374,602),
state 0x1, keycode 38 (keysym 0x41, A), same_screen YES,
XLookupString gives 1 bytes: (41) "A"
XmbLookupString gives 1 bytes: (41) "A"
XFilterEvent returns: False
"state" reflects the which modifier key(s) are pressed. For "1" it is "shift", for "2" is "capslock", "4" is "control", "8" is "alt", "0x10" is "numlock", "0x40" is "command", etc. If multiple modifier keys are pressed, then "state" is the sum of all modifier state codes. keycode should match difinition in "./keycodes/evdev", and "keysym" should match "./symbols/pc+us+inet(evdev)".
Geometry reflect the physical shape/dimension of a specific keyboard model. Let us print a keyboard image of current keymap configuration:
[luke@rmbp kbd]$ xkbcomp -xkm :0 pc104.xkm
[luke@rmbp kbd]$ xkbprint pc104.xkm pc104.pshttp://www.x.org/releases/current/doc/kbproto/xkbproto.pdfhttp://www.x.org/releases/current/doc/kbproto/xkbproto.pdfhttp://www.x.org/releases/current/doc/kbproto/xkbproto.pdf
[luke@rmbp kbd]$ file pc104.ps
pc104.ps: PostScript document text conforming DSC level 2.0
[luke@rmbp kbd]$ gv pc104.ps

Clearly, this is not a Macbook Pro keyboard. Let us change the Geometry via "setxkbmap". Under "./geometry", there is a file named "macintosh". Within it, there is a geometry section called "macbook78". "setxkbmap" can set all five components directly via command line options "-geometry -compat -keycodes -symbols -types". But these five components are correlated together and you just can not set them separately or "setxkbmap" will refuse to take your change. It is hopless for end user to figure out how to choose correct configuration options for all 5 components.
xkb has a solution for this. For end user, they generally know the model of their keyboard, generally inscribed on the keyboard; and they will know which language they will input via keyboard. xkb provide two parameters named "model" and "layout", and provide all common options of these two parameters. Under directory "./rules", we have files named "*.lst", which is used to provide selectable options for front end application. xkb also provide corresponding rules to map "model/layout/variation/option" into 5 componetns of keymapping.
[luke@rmbp rules]$ ls -l *.lst
-rw-r--r-- 1 root root 41775 Feb 4 20:11 base.lst
-rw-r--r-- 1 root root 41775 Feb 4 20:11 evdev.lst
lrwxrwxrwx 1 root root 8 Feb 4 20:11 xorg.lst -> base.lst
Within xorg.lst(base.lst), we have keyboard model named "macbook78", and layout "us".
! model
pc101 Generic 101-key PC
pc102 Generic 102-key (Intl) PC
pc104 Generic 104-key PC
...........................
tm2030USB-102 TypeMatrix EZ-Reach 2030 USB (102/105:EU mode)
tm2030USB-106 TypeMatrix EZ-Reach 2030 USB (106:JP mode)
yahoo Yahoo! Internet Keyboard
macbook78 MacBook/MacBook Pro
macbook79 MacBook/MacBook Pro (Intl)
macintosh Macintosh
.............................
! layout
us English (US)
af Afghani
ara Arabic
al Albanian
....................
Within a general layout, you can specify small variations, like:
! variant
chr us: Cherokee
euro us: English (US, with euro on 5)
intl us: English (US, international with dead keys)
alt-intl us: English (US, alternative international)
colemak us: English (Colemak)
..................
If you want to assign some specific functions to pre-defined key combination, for examle, "ctrl+alt+bksp" will terminate X server, you can use the "options" list:
! option
grp Switching to another layout
grp:switch Right Alt (while pressed)
.................
solaris:sun_compat Sun Key compatibility
terminate Key sequence to kill the X server
terminate:ctrl_alt_bksp Ctrl + Alt + Backspace
I have external USB logitech keyboard. Let us do some experiments with logitech plugged in.
[luke@rmbp ~]$ xinput list
⎡ Virtual core pointer id=2[master pointer (3)]
⎜ ↳ Virtual core XTEST pointer id=4[slave pointer (2)]
⎜ ↳ bcm5974 id=10[slave pointer (2)]
⎜ ↳ Logitech USB Receiver id=12[slave pointer (2)]
⎣ Virtual core keyboard id=3[master keyboard (2)]
↳ Virtual core XTEST keyboard id=5[slave keyboard (3)]
↳ Power Button id=6[slave keyboard (3)]
↳ Power Button id=7[slave keyboard (3)]
↳ Sleep Button id=8[slave keyboard (3)]
↳ Apple Inc. Apple Internal Keyboard / Trackpadid=9[slave keyboard (3)]
↳ Logitech USB Receiver id=11[slave keyboard (3)]
[luke@rmbp ~]$ setxkbmap -device 9 -print
xkb_keymap {
xkb_keycodes { include "evdev+aliases(qwerty)"};
xkb_types { include "complete"};
xkb_compat { include "complete"};
xkb_symbols { include "pc+us+inet(evdev)"};
xkb_geometry { include "pc(pc104)"};
};
[luke@rmbp ~]$ setxkbmap -device 11 -print
xkb_keymap {
xkb_keycodes { include "evdev+aliases(qwerty)"};
xkb_types { include "complete"};
xkb_compat { include "complete"};
xkb_symbols { include "pc+us+inet(evdev)"};
xkb_geometry { include "pc(pc104)"};
};
xkb_keymap {
xkb_keycodes { include "evdev+aliases(qwerty)"};
xkb_types { include "complete"};
xkb_compat { include "complete"};
xkb_symbols { include "pc+us+inet(evdev)"};
xkb_geometry { include "pc(pc104)"};
};
[luke@rmbp ~]$ setxkbmap -device 11 -print
xkb_keymap {
xkb_keycodes { include "evdev+aliases(qwerty)"};
xkb_types { include "complete"};
xkb_compat { include "complete"};
xkb_symbols { include "pc+us+inet(evdev)"};
xkb_geometry { include "pc(pc104)"};
};
At this time, we can see two keyboards have identical keymap.
[luke@rmbp ~]$ setxkbmap -device 9 -model macbook78
[luke@rmbp ~]$ setxkbmap -device 9 -print
xkb_keymap {
xkb_keycodes { include "evdev+aliases(qwerty)"};
xkb_types { include "complete+numpad(mac)"};
xkb_compat { include "complete"};
xkb_symbols { include "pc+macintosh_vndr/us+inet(evdev)"};# first compile into text form, check if it is correct
[luke@rmbp xkb]$ xkbcomp -xkb -I./ keymap/macbook78 macbook78.xkb
# then compile into binary form
[luke@rmbp xkb]$ xkbcomp -xkm -I./ keymap/macbook78 macbook78.xkm
# then load it into current X to test
[luke@rmbp xkb]$ xkbcomp macbook78.xkm $DISPLAY
xkb_geometry { include "macintosh(macbook78)"};
};
Now we can see the "geometry/symbols/types" have changed. Now let us print a picture of this new layout :
![]()
Some thing unhappy happened at this time. While I check keymap of logitech keyboard, I find it get changed to "macbook78" too:
[luke@rmbp kbd]$ setxkbmap -device 11 -print
xkb_keymap {
xkb_keycodes { include "evdev+aliases(qwerty)"};
xkb_types { include "complete+numpad(mac)"};
xkb_compat { include "complete"};
xkb_symbols { include "pc+macintosh_vndr/us+inet(evdev)"};
xkb_geometry { include "macintosh(macbook78)"};
};
This is a shock for me at first sight. After a serach on google, here is why:
https://bugs.launchpad.net/ubuntu/+source/x11proto-core/+bug/120788/+activity
Quote: "
The X.org XKB protocol has a limitation in that it can map only one keyboard model and a max of 4 layouts (bug #56912) in a given X session. The data type used to communicate keyboard mappings between the server and client apps simply doesn't provide room for the data needed for multiple keyboards. So a proper solution requires updating the X11 protocol to X12 (or at least X11.1), which is something that must be done upstream (further, there is risk that changing the protocol could cause widespread breakage in client applications if not done carefully.) So, in other words, this is not something that can be trivially fixed, but it's a known issue and will hopefully be dealt with some day. "
This bug was listed in Ubuntu for more that 2 years. What can I say? Sigh... X really is aging, and it seems few people cares....
We can not have two different keymaps for different physical keyboards at the same time. So let us focus on our macbook78 keyboard. Before that, let us show an example of "variant" and "option":
http://dry.sailingissues.com/us-international-keyboard-layout.html
![]()
When "us intl" layout is in effect, "AltGr" modifier will produce the "blue characters".
We will also enable options "ctl+alt+backspace" to terminate X server.
[luke@rmbp kbd]$ setxkbmap -model pc105 -layout us -variant intl -option "terminate:ctrl_alt_bksp"
[luke@rmbp kbd]$ setxkbmap -print
xkb_keymap {
xkb_keycodes { include "evdev+aliases(qwerty)"};
xkb_types { include "complete"};
xkb_compat { include "complete"};
xkb_symbols { include "pc+us(intl)+inet(evdev)+terminate(ctrl_alt_bksp)"};
xkb_geometry { include "pc(pc105)"};
};
[luke@rmbp kbd]$ ¡²³¤€¼½¾‘’× äåé®þüúíóö«»¬ áßðfghjœ
our variant and options actually take places within (xkb_symbols). We can produce the "international" chars now. When I hit "ctrl+alt+backspace", my X server get killed and I am back to linux console.
Standard xkb setting could be done with xkbsetmap in ".xinitrc", or via systemd localectl, or via Xorg.conf. For xorg.conf, we are actually configuring the options of input driver xf86-input-evdev. For all the parameters of xf86-input-evdev, do "man evdev" and "man xkb". Install "extra/xf86-input-keyboard" so you can have "man xkb", although this driver won't get used for keyboard. evdev is the default driver for X keyboard and mouse now.
[luke@rmbp ~]$ man kbd
....................
Option "XkbRules""rules"
specifies which XKB rules file to use for interpreting the XkbModel, XkbLayout, XkbVariant, and XkbOptions settings. Default: "base" for most platforms. If you use the "base" value
then you can find listing of all valid values for these four options in the /usr/share/X11/xkb/rules/base.lst file.
Option "XkbModel""modelname"
specifies the XKB keyboard model name. Default: "pc105" for most platforms.
Option "XkbLayout""layoutname"
specifies the XKB keyboard layout name. This is usually the country or language type of the keyboard. Default: "us" for most platforms.
Option "XkbVariant""variants"
specifies the XKB keyboard variant components. These can be used to enhance the keyboard layout details. Default: not set.
Option "XkbOptions""options"
specifies the XKB keyboard option components. These can be used to enhance the keyboard behaviour. Default: not set.
I am not very fond of "xorg.conf" from the first day. Nowaday, if not for very specific reason, you should not provide a "xorg.conf", since X server most of time will work out the details most of the time. Check "/var/log/Xorg.0.log" and you can see X server most of time will choose correct setting for you.
l like systemd and I would like to put all system level setting into systemd. So :
[luke@rmbp ~]$ localectl set-x11-keymap us macbook78 "" terminate:ctrl_alt_bksp
[luke@rmbp ~]$ localectl status
System Locale: LANG=en_US.UTF-8
VC Keymap: us
X11 Layout: us
X11 Model: macbook78
X11 Variant: terminate:ctrl_alt_bksp
[luke@rmbp ~]$ setxkbmap -device 9 -model macbook78
[luke@rmbp ~]$ setxkbmap -device 9 -print
xkb_keymap {
xkb_keycodes { include "evdev+aliases(qwerty)"};
xkb_types { include "complete+numpad(mac)"};
xkb_compat { include "complete"};
xkb_symbols { include "pc+macintosh_vndr/us+inet(evdev)"};# first compile into text form, check if it is correct
[luke@rmbp xkb]$ xkbcomp -xkb -I./ keymap/macbook78 macbook78.xkb
# then compile into binary form
[luke@rmbp xkb]$ xkbcomp -xkm -I./ keymap/macbook78 macbook78.xkm
# then load it into current X to test
[luke@rmbp xkb]$ xkbcomp macbook78.xkm $DISPLAY
};

Some thing unhappy happened at this time. While I check keymap of logitech keyboard, I find it get changed to "macbook78" too:
[luke@rmbp kbd]$ setxkbmap -device 11 -print
xkb_keymap {
xkb_keycodes { include "evdev+aliases(qwerty)"};
xkb_types { include "complete+numpad(mac)"};
xkb_compat { include "complete"};
xkb_symbols { include "pc+macintosh_vndr/us+inet(evdev)"};
xkb_geometry { include "macintosh(macbook78)"};
};
https://bugs.launchpad.net/ubuntu/+source/x11proto-core/+bug/120788/+activity
Quote: "
The X.org XKB protocol has a limitation in that it can map only one keyboard model and a max of 4 layouts (bug #56912) in a given X session. The data type used to communicate keyboard mappings between the server and client apps simply doesn't provide room for the data needed for multiple keyboards. So a proper solution requires updating the X11 protocol to X12 (or at least X11.1), which is something that must be done upstream (further, there is risk that changing the protocol could cause widespread breakage in client applications if not done carefully.) So, in other words, this is not something that can be trivially fixed, but it's a known issue and will hopefully be dealt with some day. "
This bug was listed in Ubuntu for more that 2 years. What can I say? Sigh... X really is aging, and it seems few people cares....
We can not have two different keymaps for different physical keyboards at the same time. So let us focus on our macbook78 keyboard. Before that, let us show an example of "variant" and "option":
http://dry.sailingissues.com/us-international-keyboard-layout.html

When "us intl" layout is in effect, "AltGr" modifier will produce the "blue characters".
We will also enable options "ctl+alt+backspace" to terminate X server.
[luke@rmbp kbd]$ setxkbmap -model pc105 -layout us -variant intl -option "terminate:ctrl_alt_bksp"
[luke@rmbp kbd]$ setxkbmap -print
xkb_keymap {
xkb_keycodes { include "evdev+aliases(qwerty)"};
xkb_types { include "complete"};
xkb_compat { include "complete"};
xkb_symbols { include "pc+us(intl)+inet(evdev)+terminate(ctrl_alt_bksp)"};
xkb_geometry { include "pc(pc105)"};
};
[luke@rmbp kbd]$ ¡²³¤€¼½¾‘’× äåé®þüúíóö«»¬ áßðfghjœ
our variant and options actually take places within (xkb_symbols). We can produce the "international" chars now. When I hit "ctrl+alt+backspace", my X server get killed and I am back to linux console.
Standard xkb setting could be done with xkbsetmap in ".xinitrc", or via systemd localectl, or via Xorg.conf. For xorg.conf, we are actually configuring the options of input driver xf86-input-evdev. For all the parameters of xf86-input-evdev, do "man evdev" and "man xkb". Install "extra/xf86-input-keyboard" so you can have "man xkb", although this driver won't get used for keyboard. evdev is the default driver for X keyboard and mouse now.
[luke@rmbp ~]$ man kbd
....................
Option "XkbRules""rules"
specifies which XKB rules file to use for interpreting the XkbModel, XkbLayout, XkbVariant, and XkbOptions settings. Default: "base" for most platforms. If you use the "base" value
then you can find listing of all valid values for these four options in the /usr/share/X11/xkb/rules/base.lst file.
Option "XkbModel""modelname"
specifies the XKB keyboard model name. Default: "pc105" for most platforms.
Option "XkbLayout""layoutname"
specifies the XKB keyboard layout name. This is usually the country or language type of the keyboard. Default: "us" for most platforms.
Option "XkbVariant""variants"
specifies the XKB keyboard variant components. These can be used to enhance the keyboard layout details. Default: not set.
Option "XkbOptions""options"
specifies the XKB keyboard option components. These can be used to enhance the keyboard behaviour. Default: not set.
.............................
I am not very fond of "xorg.conf" from the first day. Nowaday, if not for very specific reason, you should not provide a "xorg.conf", since X server most of time will work out the details most of the time. Check "/var/log/Xorg.0.log" and you can see X server most of time will choose correct setting for you.
l like systemd and I would like to put all system level setting into systemd. So :
[luke@rmbp ~]$ localectl set-x11-keymap us macbook78 "" terminate:ctrl_alt_bksp
[luke@rmbp ~]$ localectl status
System Locale: LANG=en_US.UTF-8
VC Keymap: us
X11 Layout: us
X11 Model: macbook78
X11 Variant: terminate:ctrl_alt_bksp
localectl actually write a X keyboard config file into "/etc/X11/xorg.conf.d/00-keyboard.conf".
setxkbmap -model macbook78 -layout us -option "terminate:ctrl_alt_bksp"
3. "command" key customization
It is finally time to add my humble customization of "command" key, based on selected macbook78 configuration. Under X, I can not simply remap "command" to "control", since "command" key is well defined under X, as can be seen from the output of "xev":
KeyRelease event, serial 32, synthetic NO, window 0x1800001,
root 0xb4, subw 0x0, time 7870193, (455,915), root:(2379,955),
state 0x40, keycode 133 (keysym 0xffeb, Super_L), same_screen YES,
XLookupString gives 0 bytes:
XFilterEvent returns: False
KeyRelease event, serial 32, synthetic NO, window 0x1800001,
root 0xb4, subw 0x0, time 7870689, (455,915), root:(2379,955),
state 0x40, keycode 134 (keysym 0xffec, Super_R), same_screen YES,
XLookupString gives 0 bytes:
XFilterEvent returns: False
Within the keymap source file generate via "xkbcomp -xkb :0", we have:
#keycode
<LWIN> = 133;
<RWIN> = 134;
alias <LMTA> = <LWIN>;
alias <RMTA> = <RWIN>;
modifier_map Mod4 { <LWIN> };
modifier_map Mod4 { <RWIN> };
# symbols
key <LWIN> { [ Super_L ] };
key <RWIN> { [ Super_R ] };
# types
virtual_modifiers NumLock,Alt,LevelThree,LAlt,RAlt,RControl,LControl,ScrollLock,LevelFive,AltGr,Meta,Super,Hyper;
# compatibility
http://www.x.org/releases/current/doc/kbproto/xkbproto.pdf
interpret Super_L+AnyOf(all) {
virtualModifier= Super;
action= SetMods(modifiers=modMapMods,clearLocks);
};
interpret Super_R+AnyOf(all) {
virtualModifier= Super;
action= SetMods(modifiers=modMapMods,clearLocks);
};
These definitions basically says: " Keycode of Commnad/L/R are 133/134, with alias "LMTA/RMTA"; bothhttp://www.x.org/releases/current/doc/kbproto/xkbproto.pdf command keys are mapped to "physical" modifier key "Mod4"; the key symbols for command/L/R are "Super_L" and "Super_R"; Both "Super_L" and "Super_R" are mapped to "virtualModifier Super".
Under Xkb, the mapping between keycode and key symbols are affected by the "type" of a keycode. A type basically defines how many "levels" of mappings could one keycode has, and with what modifiers to represent which level. Types are defined in xkb_types, for example:
type "ONE_LEVEL" {
modifiers= none;
level_name[Level1]= "Any";
};
type "TWO_LEVEL" {
modifiers= Shift;
map[Shift]= Level2;
level_name[Level1]= "Base";
level_name[Level2]= "Shift";
};
type "ALPHABETIC" {
modifiers= Shift+Lock;
map[Shift]= Level2;
map[Lock]= Level2;
level_name[Level1]= "Base";
level_name[Level2]= "Caps";
};
type "CTRL+ALT" {
modifiers= Shift+Control+Alt+LevelThree;
map[Shift]= Level2;
preserve[Shift]= Shift;
map[LevelThree]= Level3;
map[Shift+LevelThree]= Level4;
preserve[Shift+LevelThree]= Shift;
map[Control+Alt]= Level5;
level_name[Level1]= "Base";
level_name[Level2]= "Shift";
level_name[Level3]= "Alt Base";
level_name[Level4]= "Shift Alt";
level_name[Level5]= "Ctrl+Alt";
};
"ONE_LEVEL" key code is the key code only produce one key symbol, irrespective of what modifier keys are pressed/locked. For example, shift/control and other modifier keys often belongs to "LEVEL_ONE".
"TWO_LEVEL" key code are affected by "Shift" modifier, with two kind/level of key symbols for one keycode.
"ALPHABETIC" type encompass all the noremal keycodes, which are affected by whether "SHITF" or "CAPLOCK" are pressed. They all have two corresponing key symbols.
If a keycode belongs to "TWO_LEVEL",you must specifiy two key symbols for it in "xkb_sysmbols" section.
Some examples:
key <AD05> {
type= "ALPHABETIC",
symbols[Group1]= [ t, T ]
};
key <RALT> {
type= "TWO_LEVEL",
symbols[Group1]= [ Alt_R, Meta_R ]
};
Besides from type/level, Xkb also have the concept of "group". One keycode could have at most 4 groups of key mapping, with levels within each group. Specific key combinations are defined to switch among groups. We only need Group 1. All physical modifiers are defined in current keyboard configuration as:
modifier_map Control { <LCTL> };
modifier_map Shift { <LFSH> };
modifier_map Shift { <RTSH> };
modifier_map Mod1 { <LALT> };
modifier_map Lock { <CAPS> };
modifier_map Mod2 { <NMLK> };
modifier_map Mod5 { <LVL3> };
modifier_map Control { <RCTL> };
modifier_map Mod1 { <RALT> };
modifier_map Mod4 { <LWIN> };
modifier_map Mod4 { <RWIN> };
modifier_map Mod5 { <MDSW> };
modifier_map Mod1 { <META> };
modifier_map Mod4 { <SUPR> };
modifier_map Mod4 { <HYPR> };
"commandL/R" have been both defined as physical modifier (Mod4) and virtual modifier (Super). But there no existing types involves "Super". Since we will only modify mapping for "up/down/left/right/delete/". The original mapping is as follows:
key <UP> { [ Up ] };
key <LEFT> { [ Left ] };
key <RGHT> { [ Right ] };
key <DOWN> { [ Down ] };
key <BKSP> {
type= "CTRL+ALT",
symbols[Group1]= [ BackSpace, BackSpace, NoSymbol, NoSymbol, Terminate_Server ]
};
UP/down/left/right does not have any type associated with them. The best way to add "command" combination with them is to define a new two level "type", add modified the original mapping accordingly:
[luke@rmbp xkb]$ cat types/macbook78
partial default xkb_types
{
virtual_modifiers Super;
type "PC_SUPER_LEVEL2" {
modifiers= Super;
map[Super]= Level2;
level_name[Level1]= "Base";
level_name[Level2]= "Super";
};
};
[luke@rmbp xkb]$ cat symbols/macbook78
partial default xkb_symbols "basic"
{
name[Group1] = "mac super";
key <LEFT> { [ Left, Home ], type[Group1] = "PC_SUPER_LEVEL2" };
key <RGHT> { [ Right, End ], type[Group1] = "PC_SUPER_LEVEL2" };
key <UP> { [ Up, Prior ], type[Group1] = "PC_SUPER_LEVEL2" };
key <DOWN> { [ Down, Next ], type[Group1] = "PC_SUPER_LEVEL2" };
};
Since <BKSP> has type "CTRL+ALT" already, with level 1 modifier as "SHIFT". We will change the "CTRL+ALT" type definition and let "Super" act as its level 2 modifier.
type "CTRL+ALT" {SuperSuper
modifiers= Super+Shift+Control+Alt+LevelThree;
map[Super]= Level2;
preserve[Super]= Super;
map[LevelThree]= Level3;
map[Shift+LevelThree]= Level4;
preserve[Shift+LevelThree]= Shift;
map[Control+Alt]= Level5;
level_name[Level1]= "Base";
level_name[Level2]= "Super";
level_name[Level3]= "Alt Base";
level_name[Level4]= "Shift Alt";
level_name[Level5]= "Ctrl+Alt";
};
Next we will map "BKSP" level 2 symbol as "delete".
type "CTRL+ALT" {SuperSuper
modifiers= Super+Shift+Control+Alt+LevelThree;
map[Super]= Level2;
preserve[Super]= Super;
map[LevelThree]= Level3;
map[Shift+LevelThree]= Level4;
preserve[Shift+LevelThree]= Shift;
map[Control+Alt]= Level5;
level_name[Level1]= "Base";
level_name[Level2]= "Super";
level_name[Level3]= "Alt Base";
level_name[Level4]= "Shift Alt";
level_name[Level5]= "Ctrl+Alt";
};
key <BKSP> {
type= "CTRL+ALT",
symbols[Group1]= [ BackSpace, Delete, NoSymbol, NoSymbol, Terminate_Server ]
};
Now we have all mapping already, we need to combine our customized "type" and "symbols" into current key mapping, so we have a complete key mapping.
[luke@rmbp xkb]$ cat ./keymap/macbook78
xkb_keymap {
xkb_keycodes { include "evdev+aliases(qwerty)"};
xkb_types { include "complete+numpad(mac)+macbook78"};
xkb_compat { include "complete"};
xkb_symbols { include "pc+macintosh_vndr/us+inet(evdev)+terminate(ctrl_alt_bksp)+macbook78"};
xkb_geometry { include "macintosh(macbook78)"};
};
You can find all source codes under Github, follow below links:
https://github.com/lukeluo/linux-debian7-admin/tree/master/archlinux/home/luke/xkb
Now we have all the modification, we need to compile our keymap:
# first compile into text form, check if it is correct
[luke@rmbp xkb]$ xkbcomp -xkb -I./ keymap/macbook78 macbook78.xkb
# then compile into binary form
[luke@rmbp xkb]$ xkbcomp -xkm -I./ keymap/macbook78 macbook78.xkm
# then load it into current X to test
[luke@rmbp xkb]$ xkbcomp macbook78.xkm $DISPLAY
# then compile into binary form
[luke@rmbp xkb]$ xkbcomp -xkm -I./ keymap/macbook78 macbook78.xkm
# then load it into current X to test
[luke@rmbp xkb]$ xkbcomp macbook78.xkm $DISPLAY
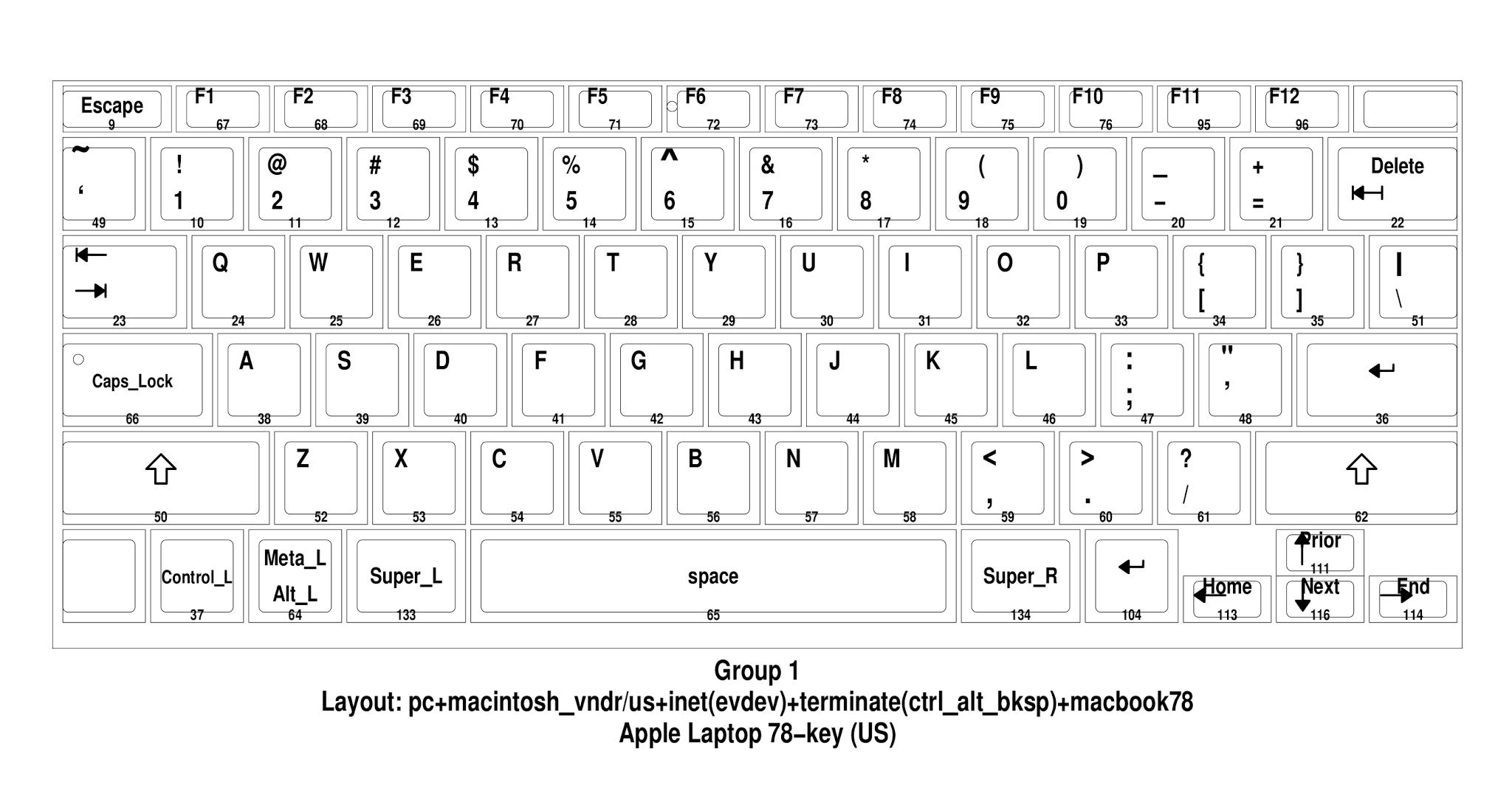
Here is the modified keymap image:
![]() You can see "Home/Prior/Next/End" attached to the "Up/Down/Left/Right" keys.
You can see "Home/Prior/Next/End" attached to the "Up/Down/Left/Right" keys.
Finally, add one line into .xinitrc:
xkbcomp macbook78.xkm $DISPLAY
I am using i3 as my window manager. Since i3 will bind to "command+up/down/left/right" too, I need to comment out i3's related key binding, so it won't override my customization.
# alternatively, you can use the cursor keys:
#bindsym $mod+Left focus left
#bindsym $mod+Down focus down
#bindsym $mod+Up focus up
#bindsym $mod+Right focus right
Finally, add one line into .xinitrc:
xkbcomp macbook78.xkm $DISPLAY
I am using i3 as my window manager. Since i3 will bind to "command+up/down/left/right" too, I need to comment out i3's related key binding, so it won't override my customization.
# alternatively, you can use the cursor keys:
#bindsym $mod+Left focus left
#bindsym $mod+Down focus down
#bindsym $mod+Up focus up
#bindsym $mod+Right focus right
Now I feel more comfortable during editing since I have both "backspace" and "delete"; In my browser, I can use "pageup/pagedown/home/end" to scroll web page precisely. Enjoy!